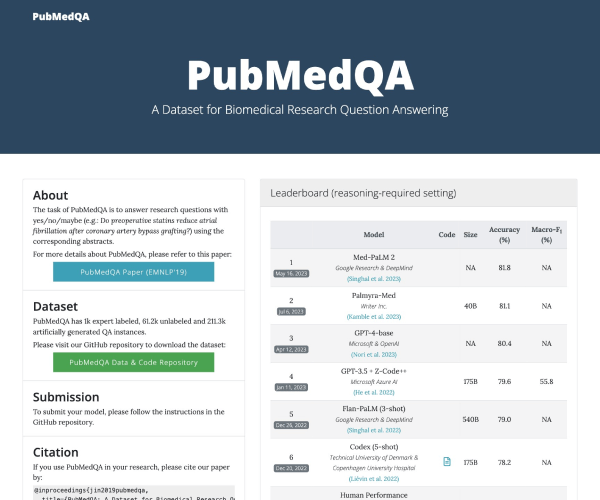
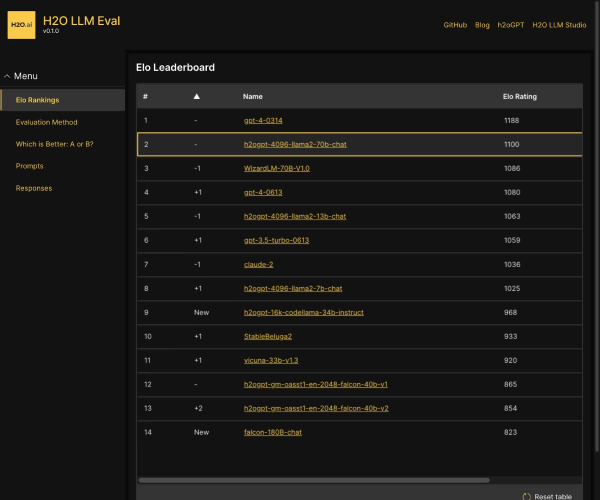
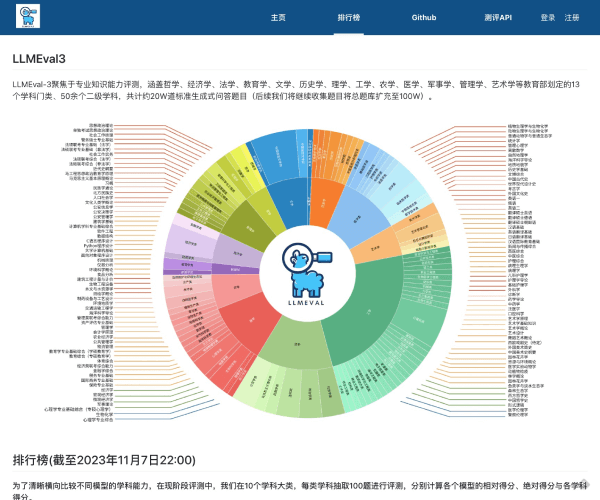
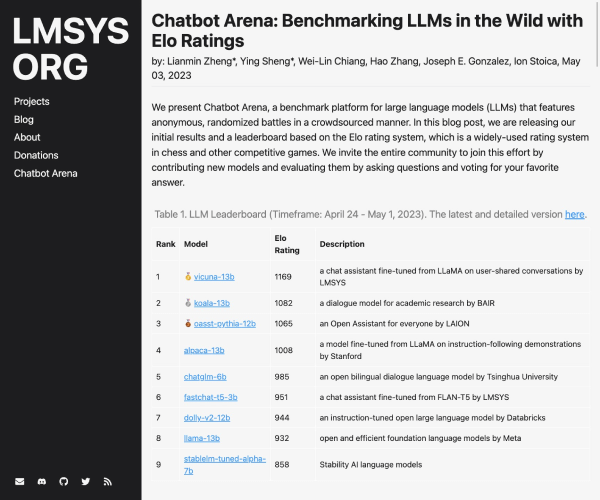
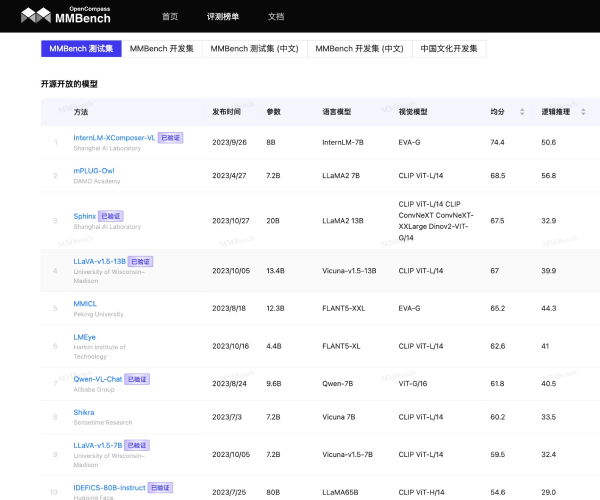
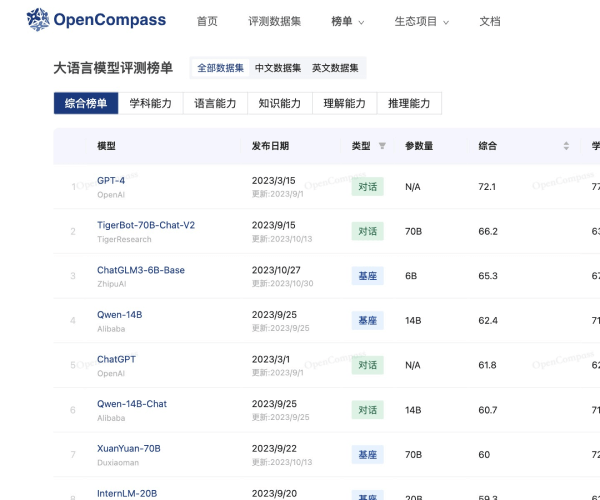
什么是HELM?
HELM,即Holistic Evaluation of Language Models(语言模型整体评估),是斯坦福大学推出的一套先进的语言模型评测体系。通过科学的方法和系统的框架,HELM致力于全面评估各类语言模型的表现,并帮助开发者和研究人员更准确地了解其模型在不同应用场景中的能力与局限性。这一评测体系为我们提供了一种标准化的方式,以便于更好地比较和优化各类语言模型。
HELM的评测组件
HELM的评估方法主要分为三个核心模块:场景、适配和指标。每次评测的运行都需要明确指定一个评测场景、对应的适配模型提示以及一个或多个性能指标。这种灵活的结构使得HELM能针对具体应用进行定制化评测,确保评测过程既高效又具针对性。
多样化的评测任务
HELM的评测范围主要覆盖英语,涵盖多种实用指标,如准确率、不确定性/校准、鲁棒性、公平性、偏差、毒性和推断效率等。其任务类型广泛,包括问答、信息检索、摘要、文本分类等,能够充分满足不同用户的需求,是各类研究与应用的理想选择。
HELM的适用人群
HELM工具特别适合研发团队、研究学者以及各类数据科学家。他们可以利用HELM提供的标准化评测,深入理解自己的语言模型在实际应用中的表现,及时调整优化策略。此外,对于企业而言,HELM也能够帮助识别模型在客户服务、自动化文档处理等领域的潜在优劣势,从而制定更高效的市场策略。
解决常见问题
常见的疑问之一是:HELM评测是否仅适用于英语模型?事实上,虽然HELM的主要评测覆盖英语,但其框架与方法论可以根据需要适配其他语言。此外,评测过程中所使用的指标与任务类型,能够根据不同场景的需求进行调整,从而保证评测的广泛适用性。
HELM的优势与价值
通过使用HELM,用户能够收获更清晰的模型表现评价,不同于传统的评测方式,HELM为您的语言模型提供了一种综合的分析视角,帮助您以数据为依据做出更明智的决策。无论是在研发新的模型,还是在优化现有的模型,HELM都将成为您不可或缺的伙伴。
结论
HELM不仅是一个语言模型评测工具,更是一把开启语言智能发展之门的钥匙。它能够帮助各界用户深入理解语言模型,使之在具体应用中获得最佳效果,为用户带来真正的价值。如果您希望提升自己语言模型的表现,HELM绝对是一个值得尝试的选择。