SuperCLUE:中文通用大模型评测基准
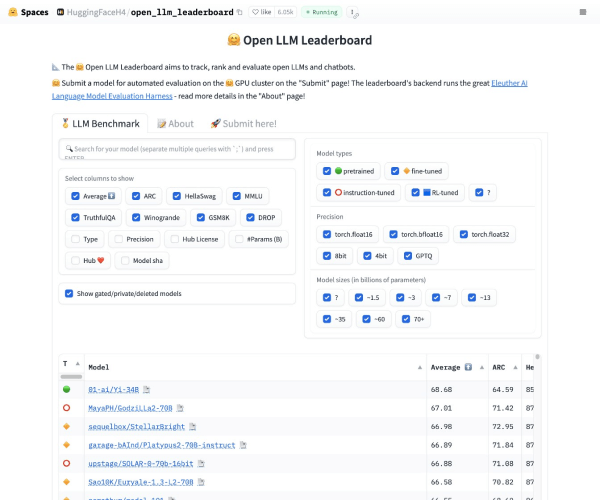
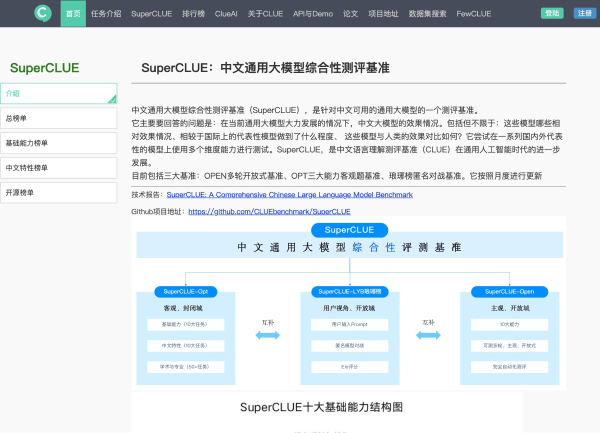
在人工智能飞速发展的今天,如何评估大模型的能力成为了一个重要话题。SuperCLUE应运而生,作为一个综合性的中文通用大模型评测基准,专门针对中文环境下模型的表现进行全面评估。它从基础能力、专业能力和中文特性能力三个维度,帮助用户直观了解模型的各项指标,确保选择合适的AI工具为工作与学习提供支持。
使用SuperCLUE,不再是单一依赖某一项技术指标。它通过细致的评测标准,涵盖了语义理解、对话、逻辑推理、角色模拟等基础能力,并且在中学与大学的专业考试中,通过50多项涵盖自然科学与社会科学的能力,赋予用户深厚的实用价值。为了满足中文使用者的独特需求,SuperCLUE还专门评测中文特性能力,确保能对成语、诗歌及文学等文化元素有精准的理解和生成能力。
评测维度详解
在基础能力方面,SuperCLUE的评测覆盖十项核心能力,包括语义理解、对话能力、逻辑推理、角色模拟、编程能力以及生成与创作等。通过这样的评估,用户可以明确了解模型在这些重要领域的性能,从而更好地使用AI工具并优化工作流程。
专业能力的广泛适用性
SuperCLUE的专业能力评估包括中学、大学及各类专业考试,涉及数学、物理、地理到社会科学等50多项能力。这一设计使得SuperCLUE不仅适用于学术研究者,也为学生备考提供了极大的支持,让他们能够在各种考试中占得先机。
中文特性能力的独特之处
为了应对具中文特点的任务,SuperCLUE特别关注评价中文特性能力。无论是成语的使用、诗歌的创作,还是对文学的理解,SuperCLUE均能进行全面评测,确保模型能够灵活运用中文,满足不同语境下的需求。
适用人群
SuperCLUE适合各类用户,无论您是学术研究者、在校学生还是企业从业人员,都能够从中获得宝贵的数据支持。通过准确的评测,用户可以提升自己的学习效果,优化工作流程,甚至开发自定义的AI应用,以适应特定的工作需求。
常见问题解答
SuperCLUE的评测结果如何使用?您可以根据评测的能力值,挑选与您需求相匹配的AI模型,保证在特定任务中获得最佳效果。
是否可以针对不同领域开展个性化评测?是的,SuperCLUE具有灵活性,您可以根据自己的需求设计专属的评测方案。
如何保障评测的准确性与公平性?SuperCLUE采用严格的评测标准,确保每个模型的表现都经过公正、透明的评判。