










什么是CMMLU?
CMMLU(中文多任务语言理解评估)是一个专为中文语言模型建立的综合性评估基准。它不仅旨在评估语言模型在中文环境中的知识水平,更重视推理能力的表现。CMMLU涵盖了67个不同主题,从基础学科到高端专业知识,确保能够全方位发掘语言模型的潜力与局限。
在多个领域,CMMLU的任务设计考虑了实际应用场景。这包括自然科学中的计算与推理问题,以及人文和社会科学中的知识性问题,还涉及到生活中常见的知识,如中国的交通法规等。因此,CMMLU不仅是对技术的考验,更是对实际应用能力的深入分析。
CMMLU的特点
CMMLU的独特之处在于其“中国特定性”。在众多任务中,许多问题的答案在中国文化和社会背景下得以验证,这些答案不一定适合其他文化或语言。这种本土化的设计使得CMMLU成为测试中文语言模型不可或缺的工具,帮助开发者更好地理解模型在中文语境中的表现。
适用人群
CMMLU适合广泛的人群,包括但不限于学术研究人员、语言模型的开发者与工程师、以及对中文自然语言处理领域感兴趣的学生与从业者。无论你是希望提升语言模型的表现,还是想深入探讨语言理解背后的逻辑,CMMLU都能为你提供宝贵的参考和实践数据。
常见问题解答
许多用户常常询问如何使用CMMLU进行评估。实际上,用户可以通过明确的任务目标、设计适合的测试场景,将模型在CMMLU下的表现与其他评估指标进行对比,从中获得对模型效果的深入理解。此外,针对特定主题的评估,还有助于开发更符合实际需求的中文语言模型。
总结
总而言之,CMMLU是一个不可或缺的有效工具,能够全面提升我们对中文语言模型的理解与使用。通过它的评估,开发者可以更精准地调整和优化模型,以实现更高的准确性与实用性。
©️版权声明:若无特殊声明,本站所有文章版权均归网点AI工坊原创和所有,未经许可,任何个人、媒体、网站、团体不得转载、抄袭或以其他方式复制发表本站内容,或在非我站所属的服务器上建立镜像。否则,我站将依法保留追究相关法律责任的权利。
类似于CMMLU的工具
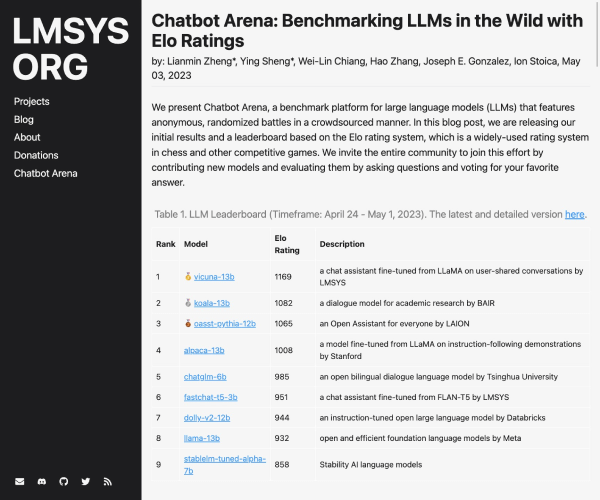

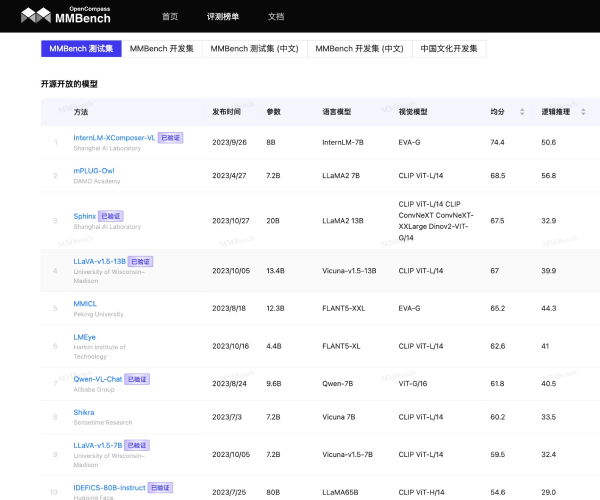
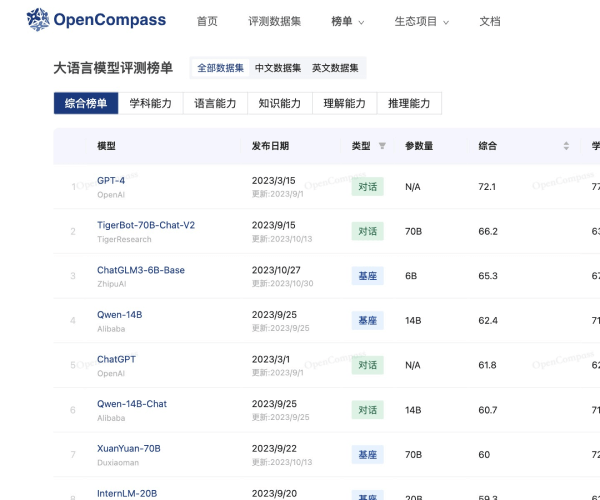

网点AI工坊导航收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,AI工具集还推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
