










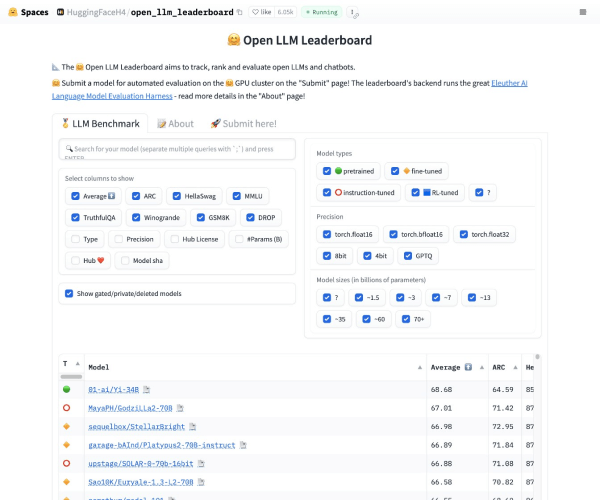
了解Open LLM Leaderboard
Open LLM Leaderboard是HuggingFace推出的领先开源大模型排行榜,它汇聚了全球最大的语言模型和数据集社区。基于Eleuther AI语言模型评估框架,这一平台旨在为用户提供真实可靠的模型性能数据,助力研究人员和开发者深入了解当前大模型的前沿进展。在这份榜单上,您可以轻松找到各种开源大型语言模型(LLM),从而选取最适合您的项目需求的工具。
具备真实性能评估的必要性
随着大型语言模型和聊天机器人的蓬勃发展,市场上充斥着对这些工具性能的夸大宣传,这使得研究者和用户在选择时面临困惑。Open LLM Leaderboard通过使用Eleuther AI语言模型评估框架,对每个模型进行四个关键基准测试,确保了对模型性能的准确评估。这统一的评估Framework为用户提供了跨任务的比较,帮助他们在各种任务中做出明智的选择,确保所选工具是真正符合需求的高效资产。
Open LLM Leaderboard的评估基准
Open LLM Leaderboard依据四项关键基准进行模型评估,各项基准的具体信息如下:
- AI2推理挑战(25-shot): 针对一组小学科学问题进行推理测试。
- HellaSwag(10-shot): 该基准测试常识推理,虽然对人类来说简单(成功率约95%),但对当前最先进的模型则充满挑战。
- MMLU(5-shot): 测量文本模型在57个任务上的多任务训练精准度,包括基本数学、美国历史、计算机科学及法律等领域。
- TruthfulQA(0-shot): 用于评估模型在克服在线常见虚假信息上的能力。
适用人群
Open LLM Leaderboard适用的用户群体广泛,主要包括研究人员、机器学习工程师、数据科学家以及任何关注大型语言模型应用与发展的从业者。无论您是希望探索最新模型的学术研究者,还是需要高效工具推动商业项目的开发者,这个平台都能够为您提供精准的信息与工具选择,助力您的创作与探究。
真实用户的体验
使用Open LLM Leaderboard后,用户常常表示其对模型的透明质量评估让他们的决策变得更加科学。例如,一位研究者在选择模型时,能迅速掌握其在实际应用中的表现,避免了传统评估方式中的盲目与误导。这样的用户体验也体现出了HuggingFace对于开源生态系统的积极推动,旨在加强社区合作,提升研究效果。
©️版权声明:若无特殊声明,本站所有文章版权均归网点AI工坊原创和所有,未经许可,任何个人、媒体、网站、团体不得转载、抄袭或以其他方式复制发表本站内容,或在非我站所属的服务器上建立镜像。否则,我站将依法保留追究相关法律责任的权利。
类似于Open LLM Leaderboard的工具
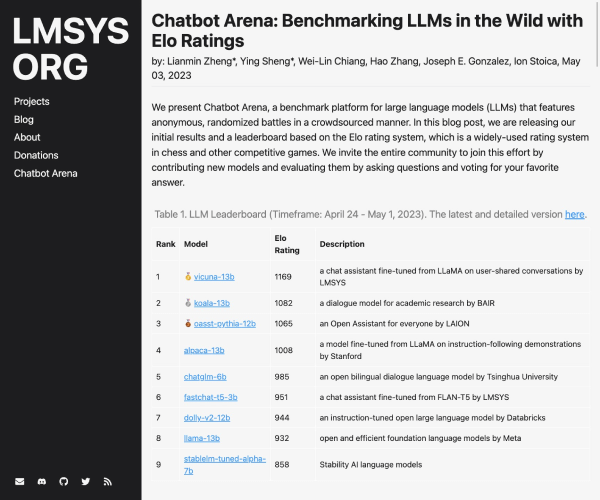

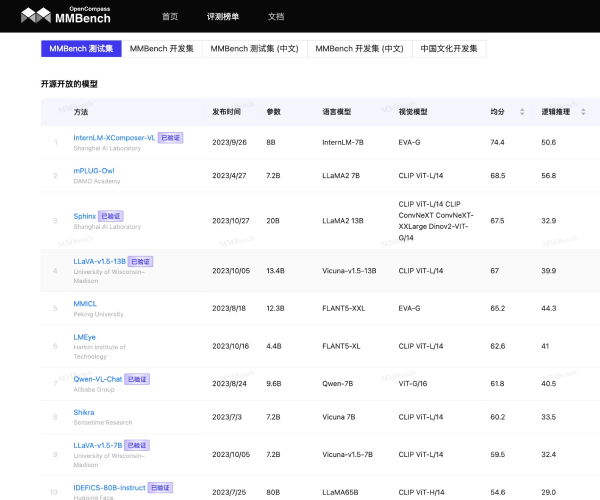
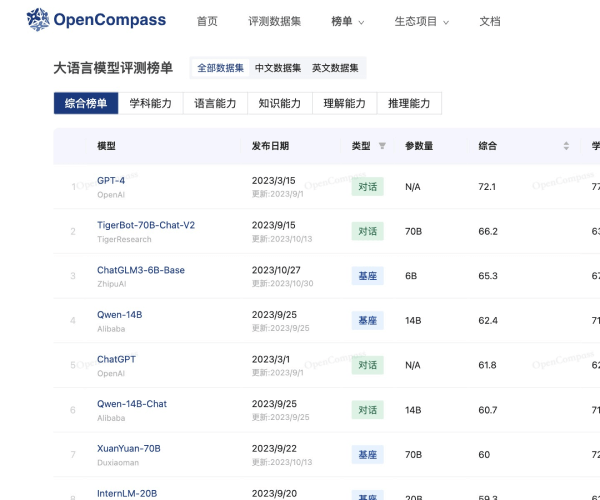

网点AI工坊导航收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,AI工具集还推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
