了解FlagEval(天秤)
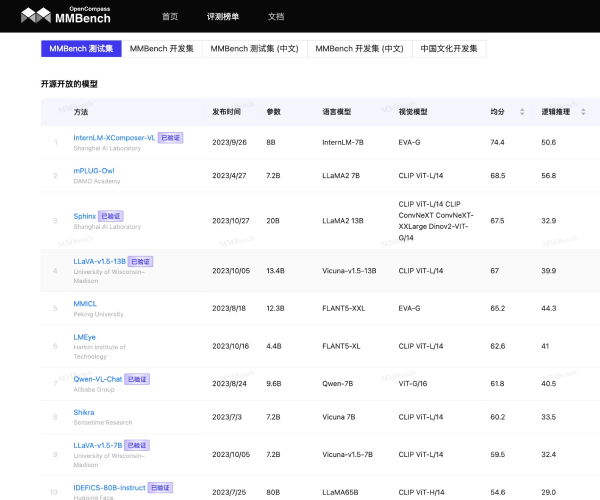
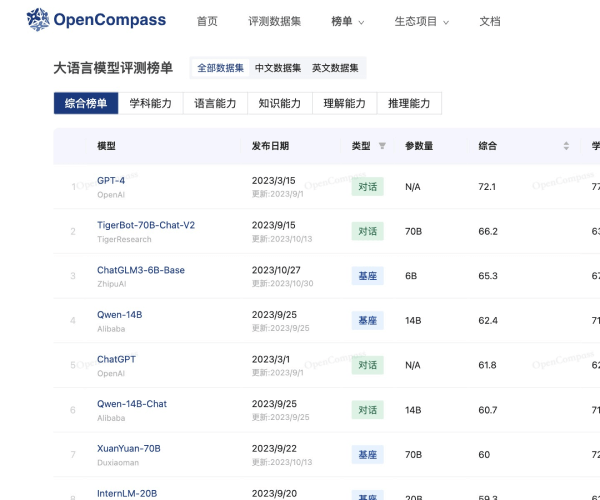
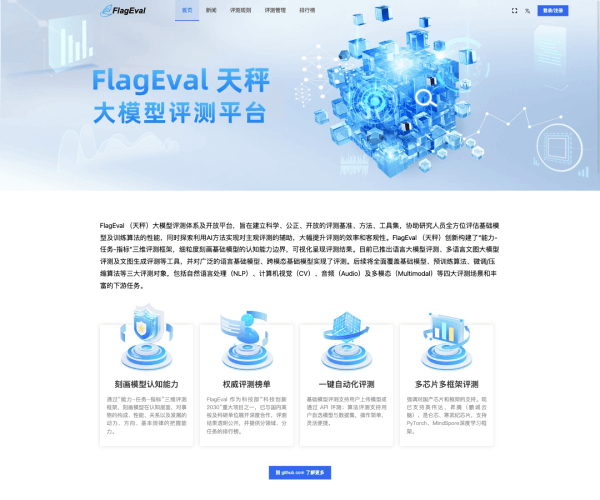
FlagEval(天秤)是由智源研究院联合众多高校团队共同开发的一款高性能大模型评测平台。它采用了全新的“能力—任务—指标”三维评测框架,为用户提供精准且全面的评测服务。无论是学术研究还是应用开发,FlagEval都能为您提供最具价值的洞察,让您在AI领域的探索中如虎添翼。
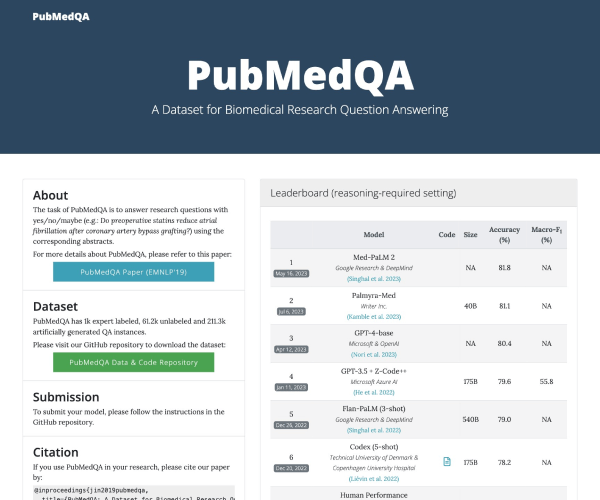
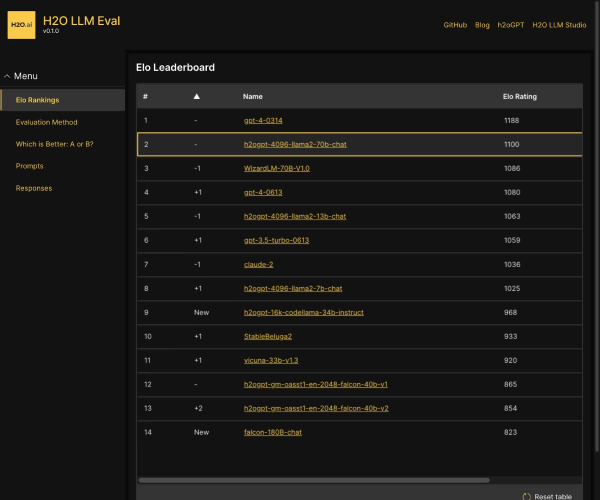
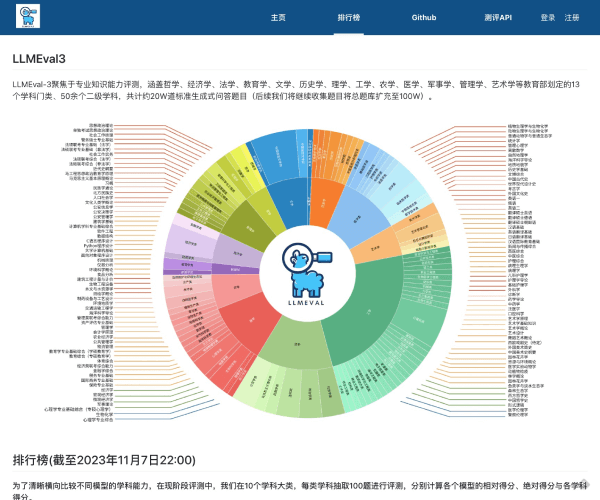
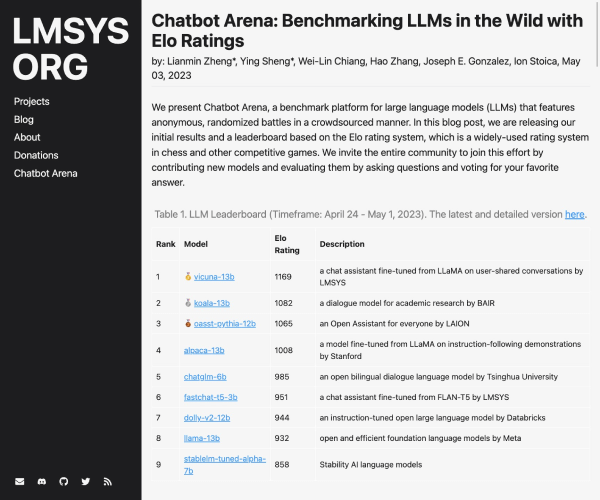
该平台现已集成30多种能力、5种任务和4大类指标,涵盖超过600个维度的全面评测体系。无论您关注的是模型的性能、实用性,还是依赖于特定数据集进行的细致考量,FlagEval都能满足您的需求。通过提供22个主客观评测数据集和84433道题目,用户将能够获取深刻的分析和评估。
功能特点
FlagEval不仅限于简单的评测,它给用户带来多维度的反馈。本平台可助力开发者在模型训练和优化过程中,实时监测其性能表现,从而深入分析模型的优劣势。这种实时的反馈机制,不仅提升了模型的效率,还降低了开发周期,使得AI工具的应用更加灵活与高效。
适用人群
无论您是研究人员、开发者还是企业用户,FlagEval都为您提供了合适的解决方案。研究者可以利用平台获得大量数据进行深层次分析;开发者则能够通过评测工具提升模型的实用性;而企业用户则可以依赖这一平台确保模型的高效率和可靠性,提升其产品的智能化水平。
常见问题解答
FlagEval如何获取评测结果?
您可以通过在平台中设定特定的能力和任务,系统将自动为您提供相应的评测结果。这些结果将帮助您更好地理解模型的表现和优化空间。
使用FlagEval是否需要技术背景?
不需要,FlagEval的设计旨在使得所有用户均能轻松上手。无论您是AI领域的新手还是经验丰富的专业人士,都能快速掌握该平台的使用技巧。
总结
总之,FlagEval(天秤)作为一款功能强大的大模型评测平台,正在改变AI模型评测的传统方式。其全面的评测维度和高效的任务设计,为科研和实践者提供了巨大的便利。无论您处于哪个领域,FlagEval必将为您带来全新的体验,助您在人工智能的旅程中不断前行。