MMLU简介:评测语言理解能力的金标准
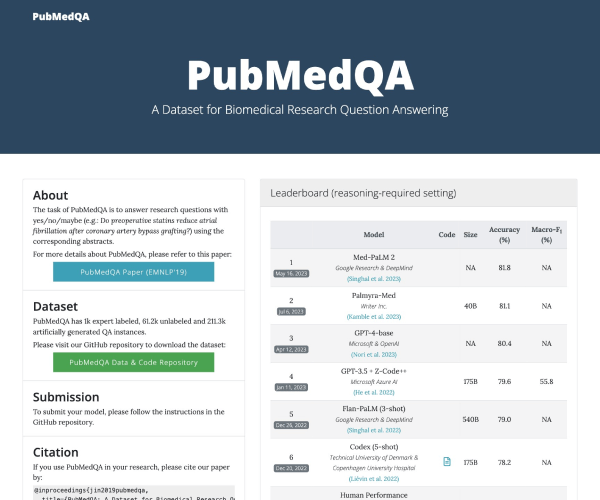
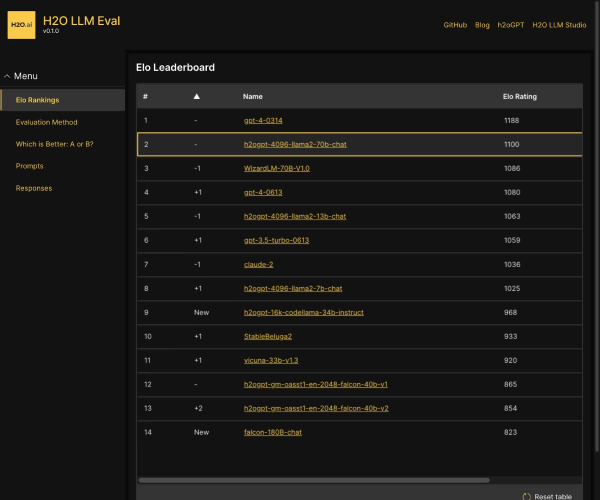
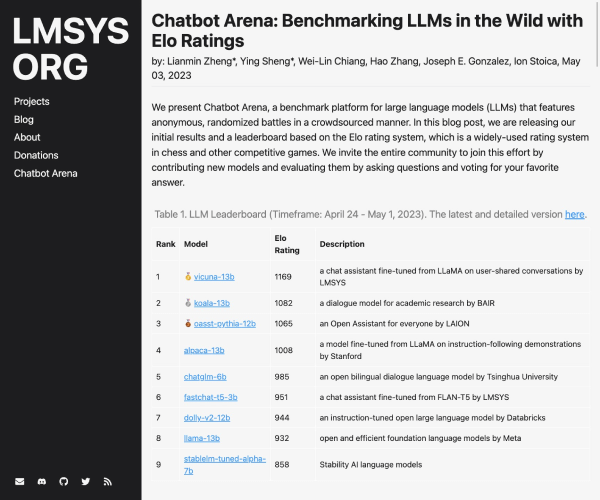
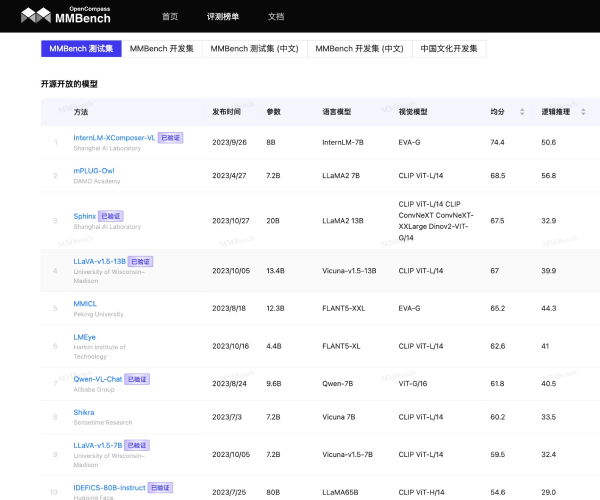
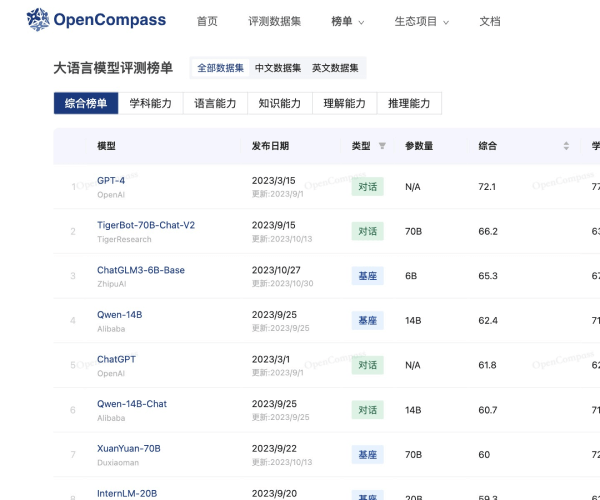
在当今人工智能迅猛发展的时代,如何衡量大模型的语言理解能力成为了研究人员的重要课题。MMLU(Massive Multitask Language Understanding)应运而生,它是由加州大学伯克利分校的研究团队于2020年9月推出的,旨在评估大模型在多样化任务中的表现。该测评已成为业界颇具权威性的语言理解测评之一,关注的不仅是模型的准确性,更是其在广泛知识领域中的应用能力。
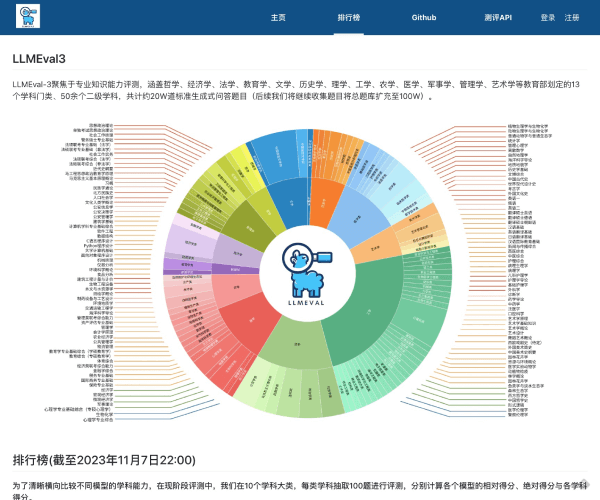
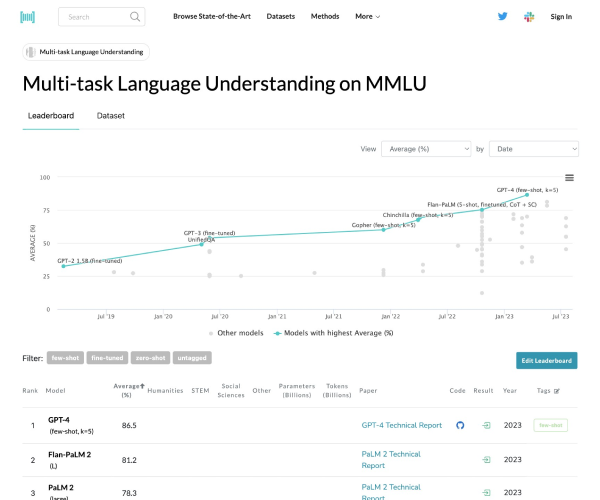
MMLU测试覆盖了57项任务,内容涉及初等数学、美国历史、计算机科学及法律等多个领域。这种广泛的任务设置使得评测不仅仅局限于单一的知识领域,而是对模型的全面理解能力进行了深入的考察。通过英语进行评测,MMLU能够有效地展现出模型在语言表达和逻辑推理方面的能力。
MMLU的核心任务与意义
MMLU的关键任务在于对大模型的知识覆盖范围和理解能力进行细致评估。通过设置多种任务,MMLU不仅可以帮助我们了解模型在只掌握部分知识时的表现,还能评估其在面对不熟悉问题时的应对策略。这种全面的测试方式,不仅为研究人员提供了深入分析的基础,也为开发更智能的语言模型提供了重要的参考。
场景化的用户体验:谁会从MMLU中受益?
无论您是从事学术研究的科研人员,还是希望未来利用AI技术提升工作效率的行业专家,MMLU所提供的丰富数据与分析结果都将成为您评估和优化语言模型的重要工具。通过MMLU,不仅可以检验当前大模型的能力,还能为未来的发展方向提供数据支持,让对模型运用有着更直观的理解与把握。
适用人群:MMLU的多样化应用
对于学术界、企业研发团队以及AI爱好者们来说,MMLU都是一个极具价值的工具。学者们可以利用MMLU的测评结果进行深入研究,产业界的开发人员能够借助该测评结果优化AI应用,而对AI技术感兴趣的个人用户也能通过了解MMLU来提升自身的认知水平。这种多样化的适用性,使得MMLU在不同领域得到了广泛的认可和应用。
频繁问答:用户常见疑问解答
在使用MMLU时,用户常常会有一些疑问。例如,如何获取MMLU的测评数据?首先,这些数据通常通过平台公布,用户可以根据需求下载相关资源。如何理解测试结果?了解结果需要结合相应领域的知识,分析模型在各项任务中的表现,进而得出结论。最后,MMLU是否会持续更新?是的,随着大模型的发展,MMLU也会进行定期更新,以保持其在评测领域的权威性和前瞻性。